15. Juni 2026
Kleine Modelle für große Aufgaben
![]()
Teilnahme am Build Small Hackathon. Bild: Hugging Face.
Wir wollten uns intern mit den aktuellen Fähigkeiten kleiner Sprachmodelle (SLMs) vertraut machen. Als Hugging Face zum Build Small Hackathon aufgerufen hat, war dies die perfekte Gelegenheit. In diesem Blog berichten wir über unsere Teilnahme und zeigen, welche Erkenntnisse wir aus diesem Event gewonnen haben.
Die Aufgabe: Think small
Während die Frontier-Modelle immer größer werden, ging es hier explizit darum, nur kleine Modelle mit weniger als 32 Milliarden Parametern zu verwenden.
Dabei gab es zwei Tracks:
- Backyard AI: Ein echtes Problem lösen
- An Adventure in Thousand Token World: Etwas Wunderschönes erschaffen
Zahlen für Zahlenfanatiker
- 5.–15. Juni (Wir haben insgesamt 3 Tage mitgemacht)
- $48.000+ Preisgeld
- Mehr als 2.000 Teilnehmer
- 6 Bonus Quests (z. B. Fine-Tune eines eigenen Modells verwenden)
Unsere Idee: Smolnalysis
Übersetzung in OpenUI-Lang
Als Basis wollten wir ein Modell fine-tunen, das natürliche Sprache direkt in OpenUI-Lang übersetzt.
OpenUI ist ein generatives UI-Framework, das Frontendkomponenten dynamisch mit einem LLM generiert. Die zugrunde liegende Abstraktionssprache OpenUI-Lang ist dabei deutlich token-effizienter als beispielsweise direktes HTML-Rendering.
Ein kurzes Beispiel zeigt das Prinzip:
Beispiel: Wetterabfrage in OpenUI-Lang
Die Nutzerfrage lautet:
Wie ist das Wetter in München
Das LLM erzeugt daraufhin mithilfe von Wetterdaten eine OpenUI-Lang-Repräsentation:
root = Stack([header, callout, cards, footer])
header = CardHeader("Wetter in München", "Aktuelle Vorhersage — heute")
callout = Callout("info", "Hinweis", "Dies sind typische Wetterwerte für München. Für Echtzeit-Daten bitte einen Wetterdienst besuchen.")
cards = Stack([tempCard, windCard, humCard, uvCard], "row", "m", "stretch", "start", true)
tempCard = Card([CardHeader("🌤️ Temperatur", "Teilweise bewölkt"), TextContent("14 °C", "large-heavy"), TextContent("Gefühlt: 12 °C", "small")], "card")
windCard = Card([CardHeader("💨 Wind", "Aus Nordwest"), TextContent("18 km/h", "large-heavy"), TextContent("Böen bis 30 km/h", "small")], "card")
humCard = Card([CardHeader("💧 Luftfeuchtigkeit", "Mäßig"), TextContent("62 %", "large-heavy"), TextContent("Taupunkt: 7 °C", "small")], "card")
uvCard = Card([CardHeader("☀️ UV-Index", "Niedrig"), TextContent("2", "large-heavy"), TextContent("Kein Sonnenschutz nötig", "small")], "card")
footer = Card([CardHeader("5-Tage-Vorschau", ""), forecastChart], "sunk")
forecastChart = BarChart(["Mo", "Di", "Mi", "Do", "Fr"], [highSeries, lowSeries], "grouped", "Wochentag", "Temperatur (°C)")
highSeries = Series("Hoch (°C)", [14, 16, 13, 11, 12])
lowSeries = Series("Tief (°C)", [7, 9, 8, 5, 6])Im Frontend gerendertes Ergebnis:
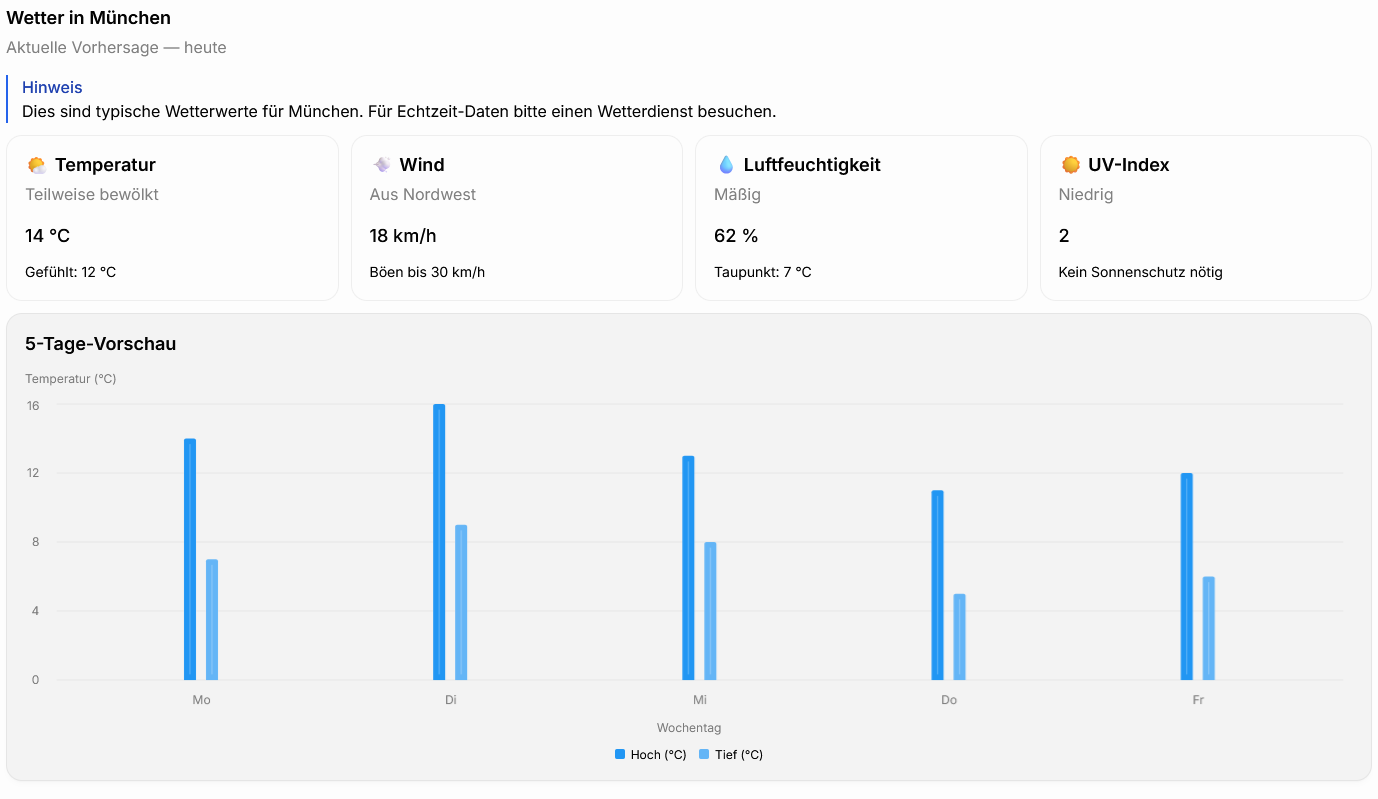
Statt ein großes LLM mit einem ausführlichen Systemprompt einzusetzen, der die Funktionsweise von OpenUI-Lang erklärt, wollten wir ein SLM trainieren, das die Kombination aus Nutzerfrage und relevantem Kontext direkt in OpenUI-Lang übersetzt.
Kombination mit dem OpenData-Katalog der LHM
Damit wir einen sinnvollen Use Case für den Backyard AI Track hatten, wollten wir einen Agenten bauen, der bei Fragen zu Datensätzen in einem Open-Data-Portal hilft. Konkret sollte er mit https://opendata.muenchen.de/ interagieren, das auf CKAN basiert.
Mehr Informationen zur CKAN-Schnittstelle
Die Daten sind dort nach Gruppen und Tags organisiert, zum Beispiel über die Gruppe Verkehr: https://opendata.muenchen.de/group/tran oder über Tags wie https://opendata.muenchen.de/dataset/?tags=Fahrrad. Über einen Query-Endpunkt lassen sich passende Datensätze suchen und anschließend herunterladen.
Umsetzung
Architektur
Ein zentrales Deliverable im Hackathon war ein eigener Gradio Space zum Austesten. Da wir zusätzlich ein eigenes, angepasstes Frontend für das Rendering von OpenUI-Lang mitliefern wollten, haben wir uns für gr.Server entschieden. Der eigentliche Agent läuft auf dem gr.Server und verbindet sich mit den relevanten Sprachmodellen, die auf ZeroGPU-Instanzen laufen.
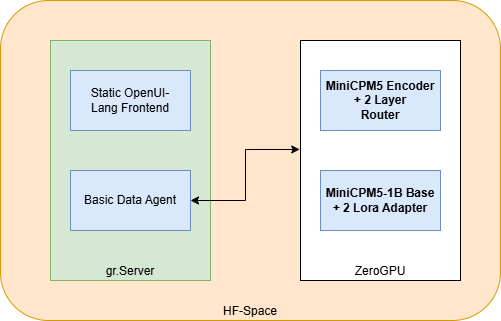
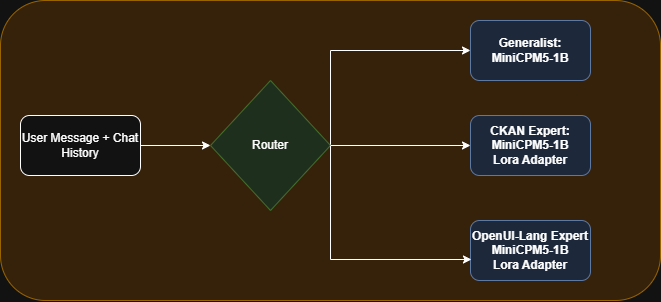
Wir haben uns bewusst für den Einsatz von MiniCPM-1B sowie feinabgestimmten LoRA-Adaptern entschieden. Dies hat zwei Gründe: Zum einen hat der Anbieter des Modells den Hackathon unterstützt, zum anderen wollten wir testen, wie leistungsfähig ein 1B-Modell in der Praxis sein kann. Durch die Nutzung von LoRA-Adaptern konnten wir dabei besonders effizient arbeiten und erhebliche Ressourcen während der Laufzeit sparen. Zusätzlich haben wir ein kleines Multilayer-Perceptron trainiert, das erkennt, welcher Adapter gerade verwendet wird.
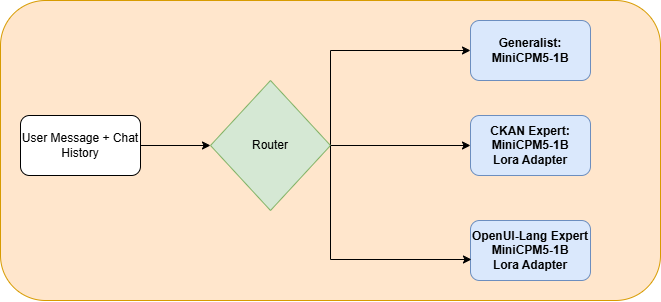
In der folgenden Grafik ist der Informationsfluss dargestellt: Der Router entscheidet, welcher Experte jeweils zum Einsatz kommt. Dabei gibt es spezifische LoRA-Adapter – einen für die Simulation der CKAN-Schnittstelle und einen für die Generierung von OpenUI-Lang.
Training
Wir haben zwei verschiedene Varianten zum Training ausprobiert. Zum einen auf lokaler Hardware. Auf der anderen Seite hatten wir auch im Zuge des Hackathons Modal Credits zur Verfüung gestellt bekommen.
Beim Training haben wir uns an das Rezept vom MiniCPM Team gehalten, welches auf TRL + PEFT basiert.
Training auf Modal
Modal ist eine serverlose Cloud-Plattform für Entwicklerinnen und Forscher, die rechenintensive Anwendungen ohne Infrastrukturaufwand betreiben möchten.
Das Deployment von lokal lauffähigem Python-Code ist dabei tatsächlich recht unkompliziert — und hat bei uns überraschenderweise im ersten Versuch funktioniert. Mit CUDA, PyTorch und Konsorten auf diversen Clustern haben wir in der Vergangenheit schon deutlich schlimmere Erfahrungen gemacht. Im Folgenden ein paar Ausschnitte aus unserem Trainingsskript:
App und Volume anlegen
app = modal.App("smolnalysis-ckan-minicpm5-lora")
volume = modal.Volume.from_name("smolnalysis-ckan-training", create_if_missing=True)Abhängigkeiten definieren
image = (
modal.Image.debian_slim(python_version="3.12")
.pip_install_from_requirements("train/ckan/requirements-train.txt")
.add_local_file("train/ckan/train_minicpm_lora.py", remote_path="/root/train_minicpm_lora.py")
...
)Funktion mit GPU-Ressourcen dekorieren
@app.function(
image=image,
gpu="A100",
timeout=60 * 60 * 4,
volumes={"/outputs": volume},
)
def train_ckan_lora(smoke: bool = True, challenge: bool = False) -> None:
...Den vollständigen Code findet ihr hier.
Kosten fallen nur während der tatsächlichen Ausführung an. Die Möglichkeit, den Serverstandort z. B. im europäischen Datenraum festzulegen, befindet sich derzeit noch in der Beta. Für das Training mit öffentlichen oder synthetischen Daten könnte Modal in Zukunft eine attraktive und kostengünstige Option sein.
Erkenntnisse
Gute Datensätze zu erstellen ist aufwändig
Das Erstellen hochwertiger Datensätze ist zeitaufwändiger als erwartet. Im Rahmen des Hackathons hatten wir schlicht nicht genug Zeit, um dies wirklich sorgfältig zu tun — unsere synthetisch generierten Datensätze waren in der Folge zu wenig realitätsnah, um die Modelle hinreichend gut zu trainieren.
Ein vielversprechenderer Ansatz wäre es gewesen, die Anwendung zunächst vollständig mit einem generischen LLM aufzubauen, echte Nutzungsinteraktionen zu sammeln und diese anschließend als Trainingsdaten für das Fine-Tuning kleiner Modelle zu verwenden. Genau dieses Vorgehen beschreibt der Ansatz aus Small Language Models are the Future of Agentic AI: Erst Daten in der Praxis sammeln, dann destillieren.
Training von SLMs ist günstig
Das Erstellen von Datensätzen mit LLMs ist überraschend günstig. Für die CKAN-Schnittstelle haben wir z. B. über mehrere Iterationen rund 3.000 Trainingsbeispiele mit mistral-medium generiert (Mehr dazu) — Gesamtkosten: ca. 5 €.
Das anschließende Training und die Evaluierung des CKAN-Fine-Tunes über Modal haben ebenfalls nur rund 5 $ gekostet.
Weniger ist mehr
Wir haben uns zu viel vorgenommen. Das Erstellen eines hochwertigen Datensatzes für nur eines unserer Modelle hätte mehr Zeit erfordert, als wir für den gesamten Hackathon eingeplant hatten. Die bessere Entscheidung wäre gewesen, sich auf ein einziges Modell für eine klar abgegrenzte Aufgabe zu konzentrieren, statt mehrere voneinander abhängige Expertenmodelle parallel zu trainieren.
Codex
Im Zuge des Hackathons wurden uns Codex Credits zur Verfügung gestellt.
Positiv aufgefallen ist:
- Codex war sehr gut darin, auch bei langlaufenden Entwicklungssessions den Gesamtkontext im Blick zu behalten.
- Trainingsskripte konnten weitgehend automatisch mithilfe der mitgelieferten Skills (MiniCPM-Fine-Tuning) erstellt werden.
Negativ aufgefallen ist:
- Es ist schwierig, bei der Masse an KI-Änderungen den Überblick über den Code zu behalten und später von Hand nachzujustieren.
- Man verliert etwas die Intuition dafür, was gut funktioniert. Insbesondere beim Erstellen der Datensätze für das Training der Modelle ist weiterhin viel menschliche Kontrolle notwendig.
Fazit & Ausblick
Der Hackathon war für uns eine gute Gelegenheit, wieder ein paar Tage gutes, ehrliches Modelltraining zu betreiben. Wie in den alten Zeiten, als noch mehr von Machine Learning als von GenAI die Rede war, gilt dabei weiterhin: Modelle sind nur so gut wie die Daten. Für die Erstellung wirklich hochwertiger Datensätze hätten wir uns rückblickend deutlich mehr Zeit nehmen müssen.
Gleichzeitig war für uns eine wichtige Erkenntnis, dass das Training kleiner Modelle nicht teuer sein muss. Für klar abgegrenzte Aufgaben lassen sich SLMs heute mit überschaubarem Aufwand trainieren. Spezialisierte Anbieter wie Modal nehmen einem dabei einen großen Teil der Hardware-Abstraktion ab, sodass man sich deutlich weniger mit CUDA-Versionen und ähnlichen Infrastrukturfragen herumschlagen muss.
Gerade in einer Zeit, in der die Nutzung großer Foundation-Modelle über API-Zugriffe tendenziell eher teurer als günstiger wird, könnte sich der Blick dadurch wieder stärker auf kleine, fein abgestimmte Modelle richten. Sie benötigen deutlich weniger Ressourcen und lassen sich auch ohne riesige GPU-Cluster produktiv einsetzen. Der Preis dafür ist allerdings eigenes Know-how sowie Zeit für sorgfältige Datenarbeit, Training, Evaluation und Wartung.
Limitierungen
Die entwickelten Adapter sind in ihrer aktuellen Form Prototypen und sollten nicht produktiv eingesetzt werden. Der Grund liegt in der Qualität der Trainingsdaten: Unsere synthetisch generierten Beispiele sind zu weit entfernt von realen Nutzungsszenarien, sodass die Generalisierungsfähigkeit der Modelle noch zu schwach ist.
Darüber hinaus fehlt eine systematische Evaluierung. Wir haben beispielsweise nicht verglichen, wie unterschiedliche Basismodelle mit denselben Trainingsdaten funktionieren würden. Auch verschiedene Modellgrößen oder Modelle mit anderem Hintergrundwissen haben wir nicht untersucht. Auch der Vergleich zu großen, kommerziellen Sprachmodellen fehlt.
Ausblick
Für uns war der Hackathon deshalb weniger ein abgeschlossener Prototyp als vielmehr ein Lernprojekt mit klaren nächsten Schritten. Besonders spannend wäre es, die Datensatzerstellung systematischer anzugehen, reale Nutzungsdaten aus einer ersten Anwendungsversion zu sammeln und darauf aufbauend gezielter zu trainieren.
Darüber hinaus wollen wir weiter beobachten, für welche kommunalen oder verwaltungsnahen Anwendungsfälle kleine Modelle tatsächlich eine belastbare Alternative zu großen, über Cloud APIs bereitgestellten Modellen sein können.
Links
- Basismodell MiniCPM5-1B
- LoRA Adapter:
- GitHub-Repo mit dem gesamten Projekt (inklusive experimenteller Artefakte für ganz Mutige)
- Hugging Face Space zum Ausprobieren
Autor*innen