23. Juli 2025
Unser Open Source KI-Stack
Seit der Veröffentlichung von ChatGPT haben generative KI-Modelle enorm an Bedeutung gewonnen. Gleichzeitig wurde die Evolution eines ganzen Ökosystems an Werkzeugen vorangetrieben, die die Fähigkeiten der Modelle einfacher und sicherer nutzbar machten. Anfangs stand dabei oft nur eine Benutzeroberfläche zum einfachen Chatten mit den großen Sprachmodellen im Fokus. Inzwischen arbeiten viele daran, KI tief in ihre Systeme zu integrieren und mithilfe von KI-Agenten Workflows zu orchestrieren.
Um diese komplexen Systeme im Enterprise-Umfeld korrekt und nachvollziehbar bereitzustellen, sind zahlreiche Funktionalitäten erforderlich. Neben Start-ups mit SaaS-Lösungen und Hyperscalern mit End-to-End-Systemen können diese auch mithilfe von Open-Source-Software-Komponenten (OSS) abgedeckt werden. OSS wahrt dabei die digitale Souveränität und hilft gleichzeitig, Kosten zu sparen.
Welchen Softwarestack das KI-Team der Stadt München für die städtischen KI-Systeme bereitstellt, erklären wir in diesem Artikel.
Motivation: GenAI wird immer komplexer
Generative KI ist ein sehr dynamisches Feld, in dem sich Technologien und Methoden rasant weiterentwickeln. Am Anfang dieser Entwicklung waren die Systeme noch einfache Wrapper, die Sprachmodelle mittels Webanwendungen zugänglich machten.
Primitives GenAI System; Quelle: Eigene Darstellung
Mit der Zeit kommen jedoch immer mehr Anforderungen hinzu, um ein vollwertiges KI-System zu betreiben. Auslöser hierfür sind nicht nur steigende Anforderungen von Nutzer*innen, sondern auch neue technische Möglichkeiten, rechtliche Anforderungen (AI Act) und die zunehmende Integration generativer KI mit Bestands-Systemen.
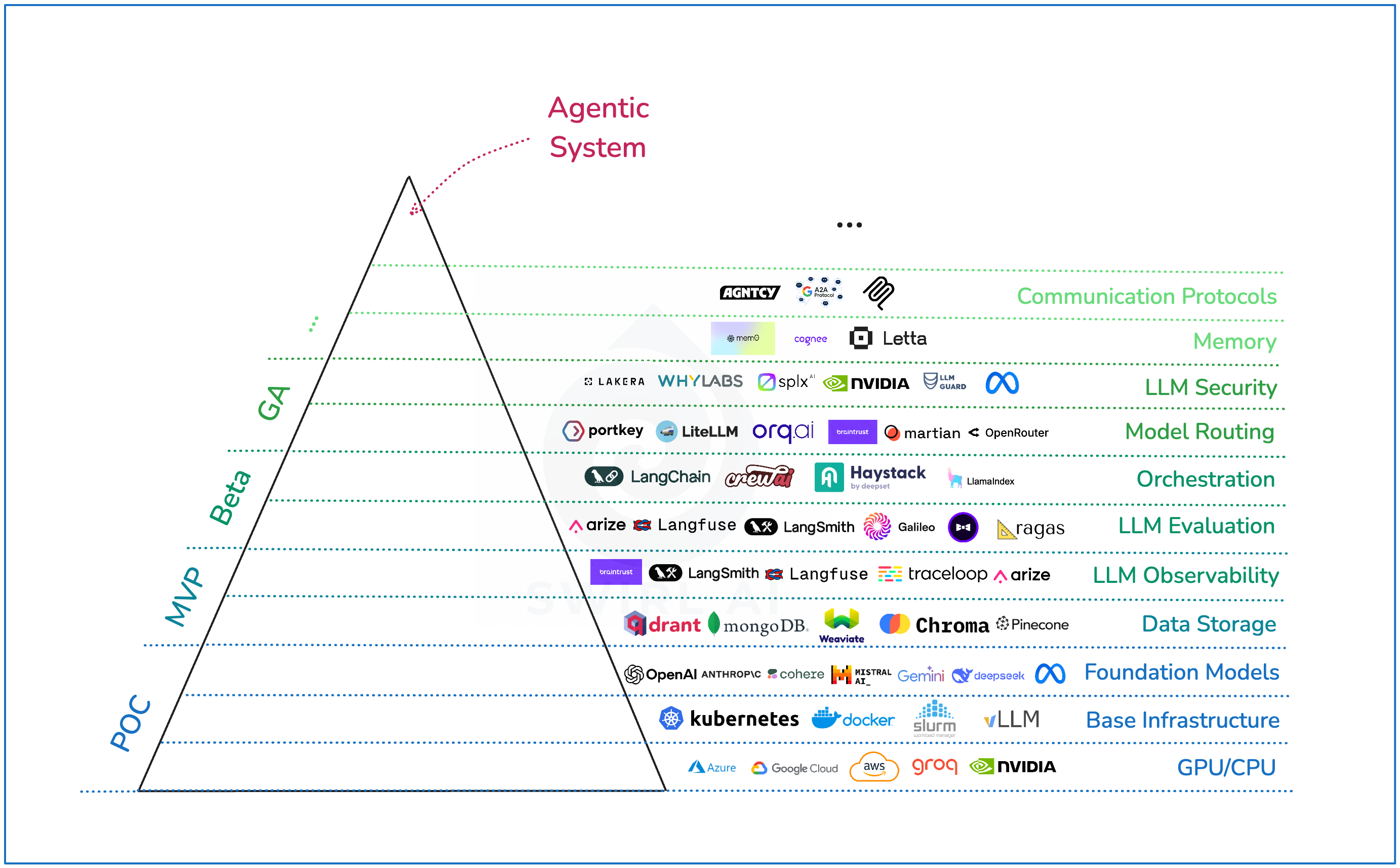
Überblick über Anforderungen und mögliche Anbieter, Quelle: SwirlAI Newsletter
Die wichtigsten Bestandteile, die in einem modernen GenAI-System benötigt werden, sind:
- Anwendungslogik und Orchestrierung: Standardisierte Frameworks und darin integrierte Abläufe, die über einzelne Anbieter hinweg möglichst einheitlich und deterministisch sind.
- KI-Modelle: Große Sprachmodelle (LLMs), Embedding-Modelle und andere spezialisierte Modelle, die im besten Fall über eine standardisierte Schnittstelle (API) aus dem gesamten Unternehmen heraus angesprochen werden können.
- Nachvollziehbarkeit & Evaluation: Der Ablauf und sowie die Ein- und Ausgaben der KI-Systeme müssen zur Sicherstellung der Nachvollziehbarkeit protokolliert und evaluiert werden.
- Persistenz: Speicherung von Dokumenten zugehörigen Suchvektoren (Embeddings) von Dokumenten
- Einlesen von Dokumenten: Extraktion von Informationen aus verschiedenen Dateiformaten (z.B. PDFs, Word-Dokumente) und deren Umwandlung in ein für die KI verständliches Format.
- Websuche: Integration von Websuchfunktionen zur Anreicherung der KI-Modelle mit aktuellen Informationen
Weitere mögliche Bestandteile, die in diesem Artikel nicht betrachtet werden:
- MCP-Registry: Das Model Context Protocol (MCP) ist ein Protokoll, das den Zugriff auf Anwendungen mittels Sprachmodellen standardisiert. Eine MCP-Registry bündelt den Zugriff auf eine Vielzahl von MCP-Services.
- Persistenz für Graphen: Mithilfe von Sprachmodellen können auch die Beziehungen von Entitäten in Texten extrahiert und in strukturierter Form als Graphen abgebildet werden. Anschließend können die extrahierten Graphen für Suchen und Analysen genutzt werden.
Ein Überblick über mögliche Komponenten (von uns verwendete Komponenten in 🟩), sowohl Open Source, als auch in ist in folgender Grafik zu finden.
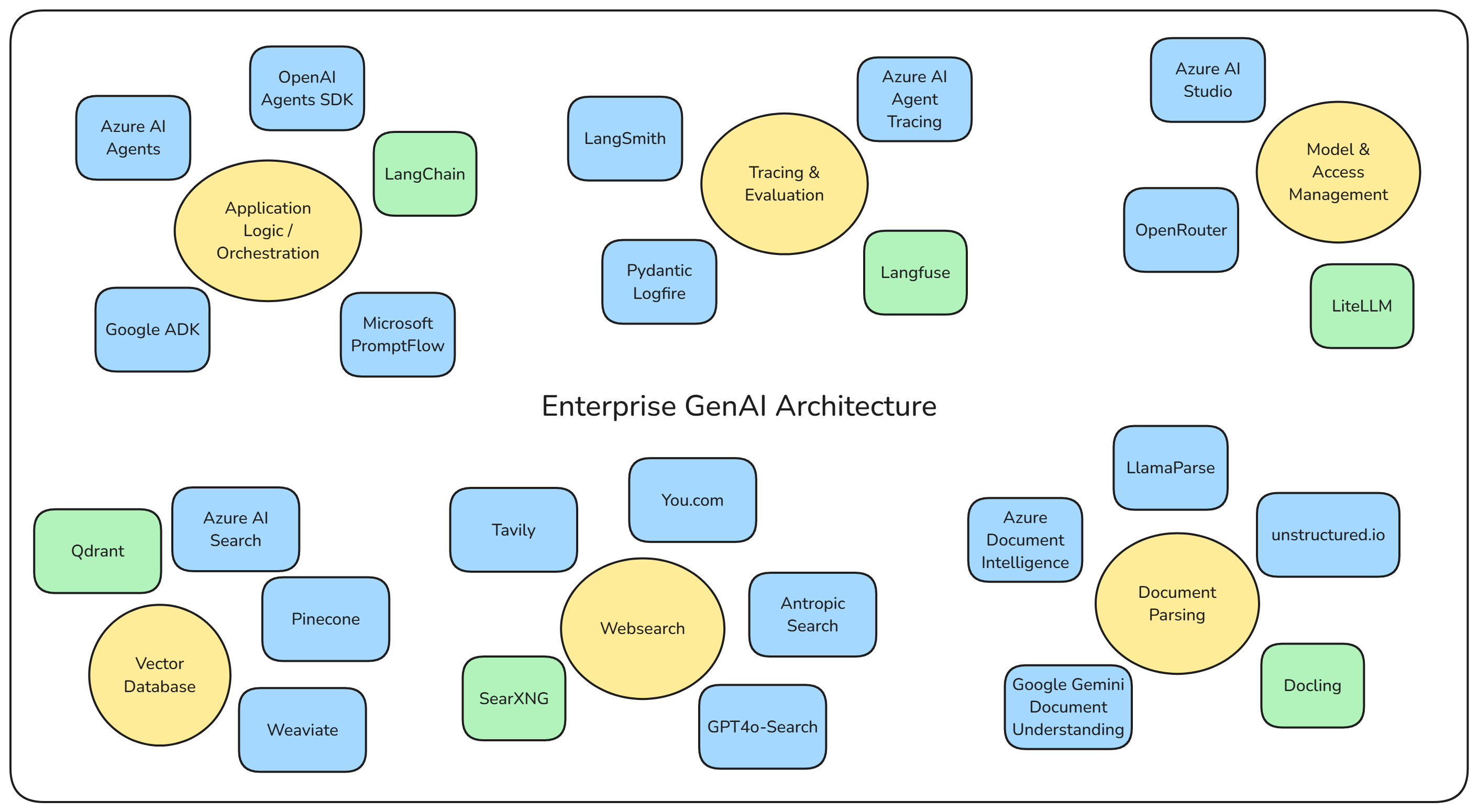
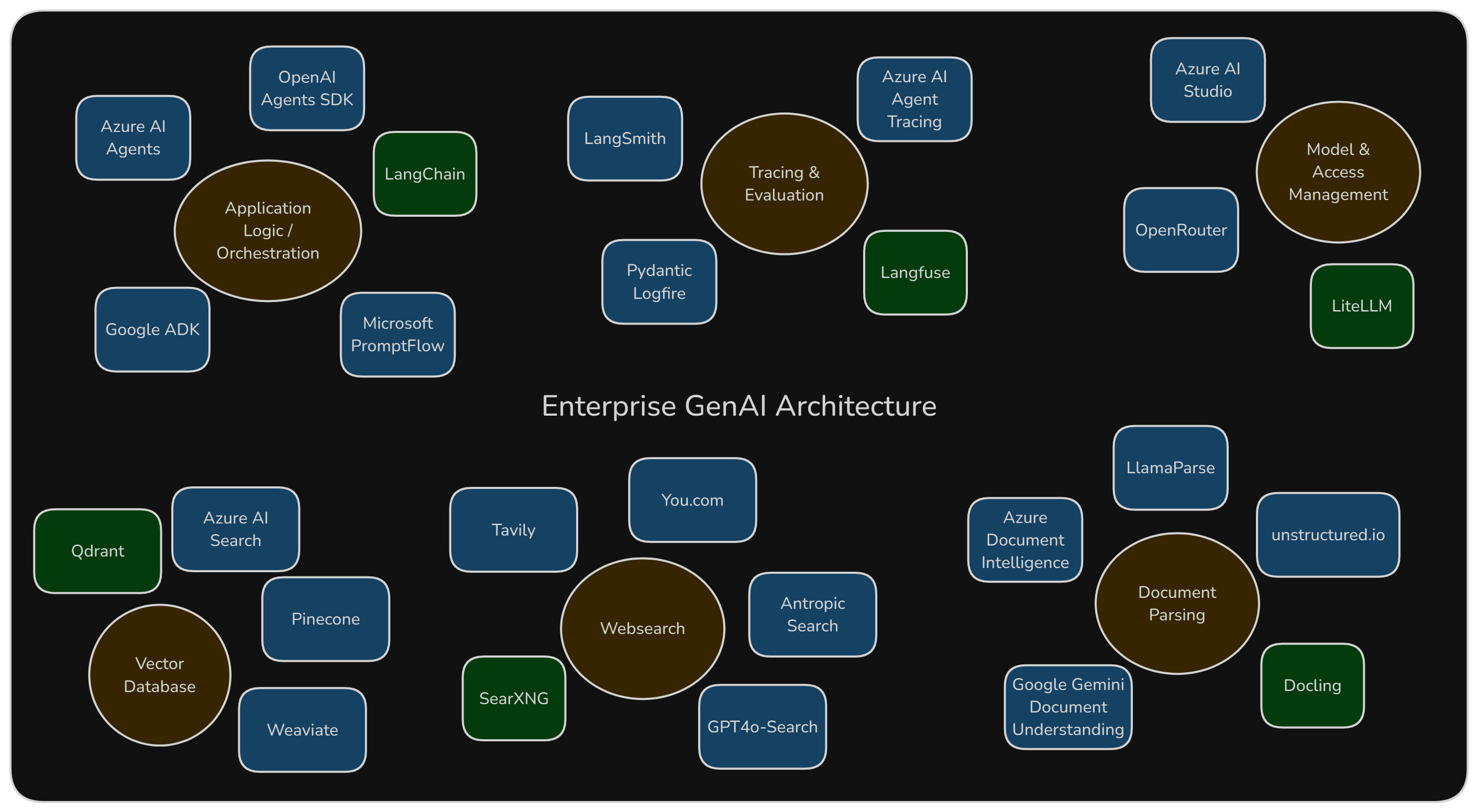
Auswahl möglicher Komponenten, Quelle: Eigene Darstellung
Der Münchner Open Source GenAI Stack
Um die digitale Souveränität der Stadt München zu wahren und gleichzeitig die Kosten im Rahmen zu halten, haben wir uns bewusst für einen Open-Source-Software-Stack entschieden.
Die einzelnen Komponenten des Stacks sind aufeinander abgestimmt und ermöglichen eine nahtlose Integration. Zentrale Komponenten stellen wir für all unsere KI-Systeme bereit, sowohl für Eigenentwicklungen als auch für Kaufsoftware. Unsere Eigenentwicklungen nutzen eine Open-Source-LLM-Orchestrierungssoftware und verwalten ihre Daten jeweils selbst.
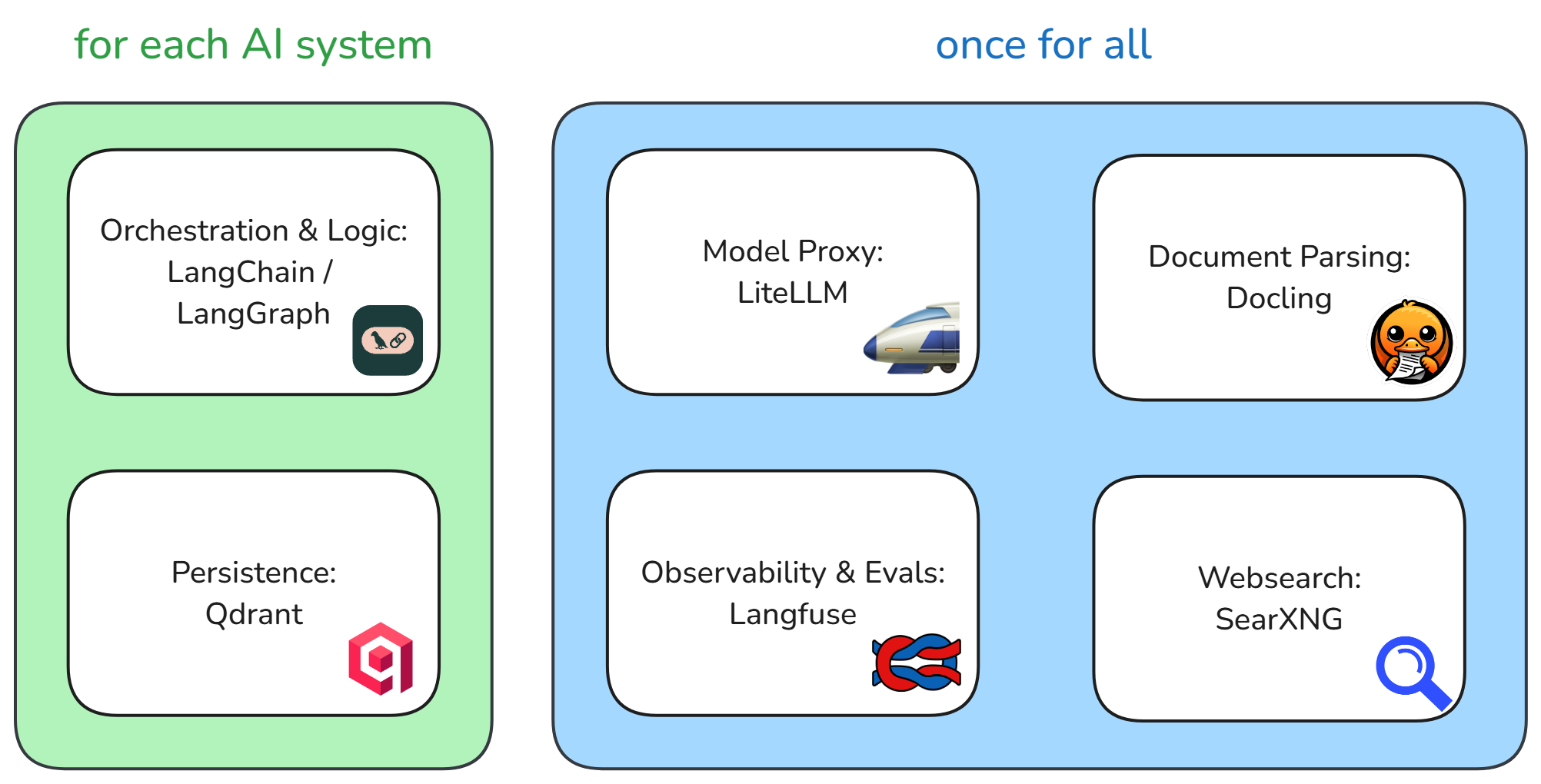
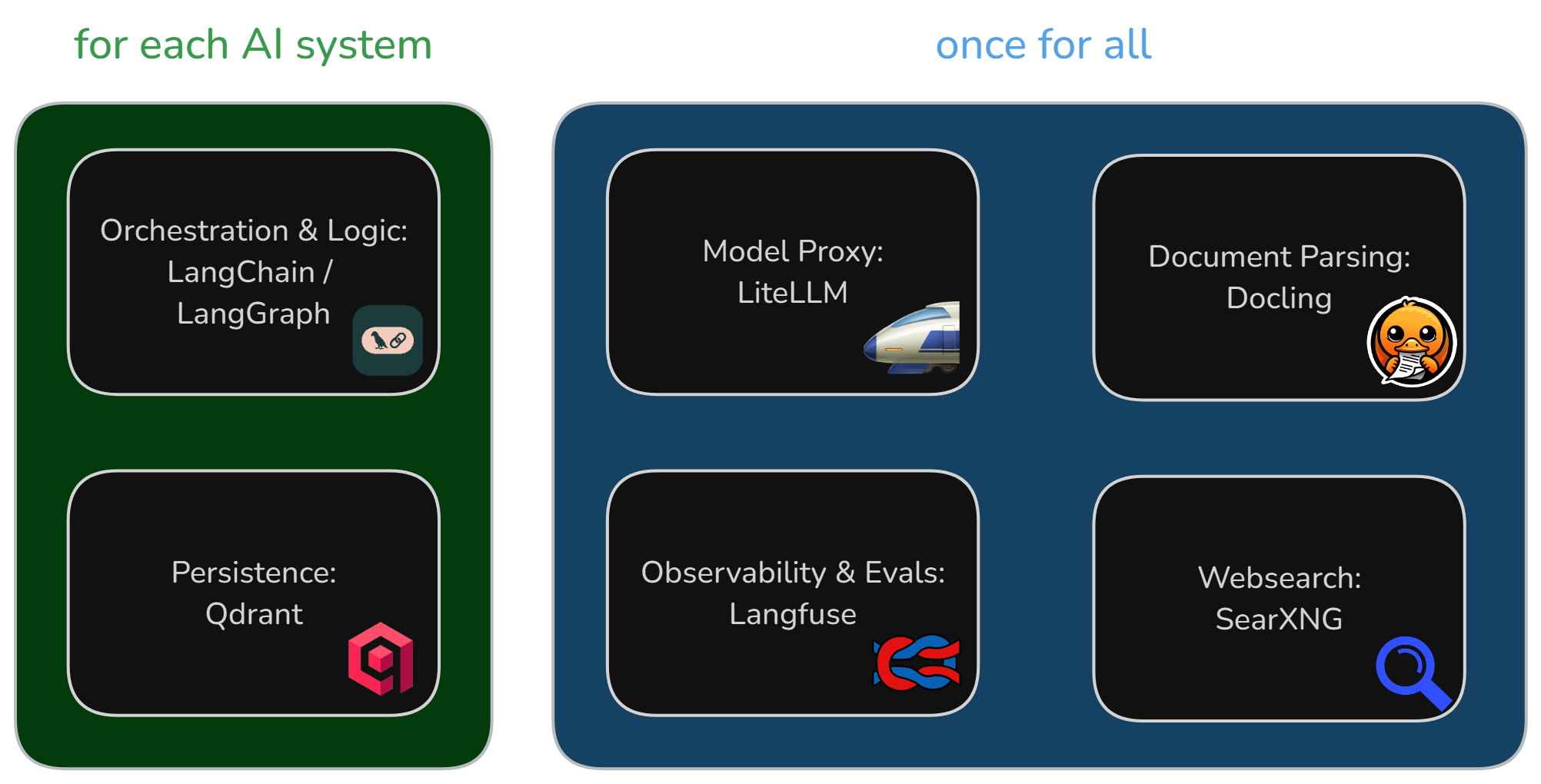
Münchner Open Source GenAI Stack, Quelle: Eigene Darstellung
🎼 Logik & Orchestrierung: LangChain & LangGraph
Um die Abhängigkeit von der API eines bestimmten Modellanbieters zu umgehen, kann der Modellzugriff mithilfe eines LLM-Integration-Frameworks wie LangChain abstrahiert werden. Das Gleiche trifft auch auf weitere Komponenten wie Vektordatenbanken zu. Darüber hinaus vereinfacht LangChain die Abbildung sequenzieller Workflows mit Sprachmodellen.
LangGraph erweitert dieses Konzept für autonome Agenten, indem Workflows nun auf Graphen basieren.
LangChainsetzen wir in der KI-Suche im Dienstleistungsfinder ein.LangGraphsetzen wir in MUCGPT ein.
💾 Persistenz: Qdrant, pgvector & Valkey
Um in einem Sprachmodell auf eigene Daten zugreifen zu können, müssen diese in den Kontext des Sprachmodells eingefügt werden. Falls mehr Daten vorhanden sind als Platz, müssen diese zunächst sinnvoll ausgewählt werden. Hierfür hat sich die Technik Retrieval Augmented Generation (RAG) etabliert, die die Auswahl der Daten mittels einer Suche trifft (Funktionsweise am Beispiel DLF).
Zuvor werden die Daten in vektorisierter Form in einer Vektordatenbank abgelegt. Pgvektor erweitert die OSS-Datenbank Postgres um diese Fähigkeiten. Wir setzen jedoch vor allem auf die Open-Source-Vektordatenbank Qdrant. Qdrant ermöglicht eine performante Suche und Filterung von Vektordaten. Zudem nutzen wir die hybride Suchfunktion, die die Kombination von Embedding-basierter Suche und klassischer Stichwortsuche ermöglicht.
Valkey ist ein Hochleistungs-Key/Value-Store, den wir vor allem zur Zwischenspeicherung kurzfristiger Informationen nutzen. Beispielsweise können damit die Zustände eines Agentensystems zwischengespeichert werden.
🧠 KI-Modellzugriff: LiteLLM
LiteLLM ist ein API-Gateway für Sprachmodelle. Es ermöglicht die Anbindung verschiedener Modellprovider wie Azure hinter einer gemeinsamen API. Dadurch ist es möglich, ohne großen Aufwand zu einem anderen Anbieter zu wechseln. Als Organisation können wir uns an dieser zentralen Stelle um den Modellzyklus kümmern und so einen Wildwuchs innerhalb unserer Organisation verhindern.
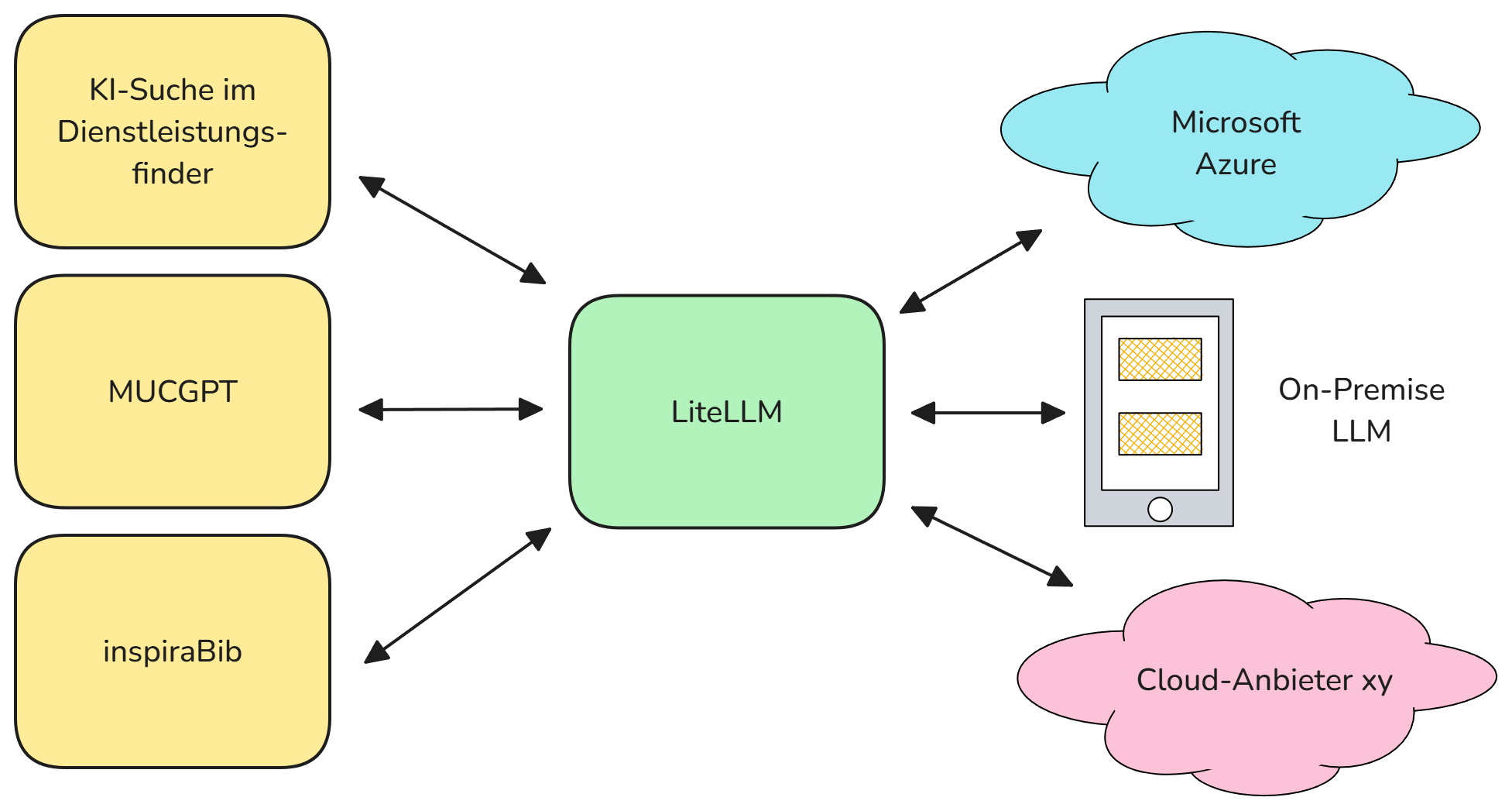
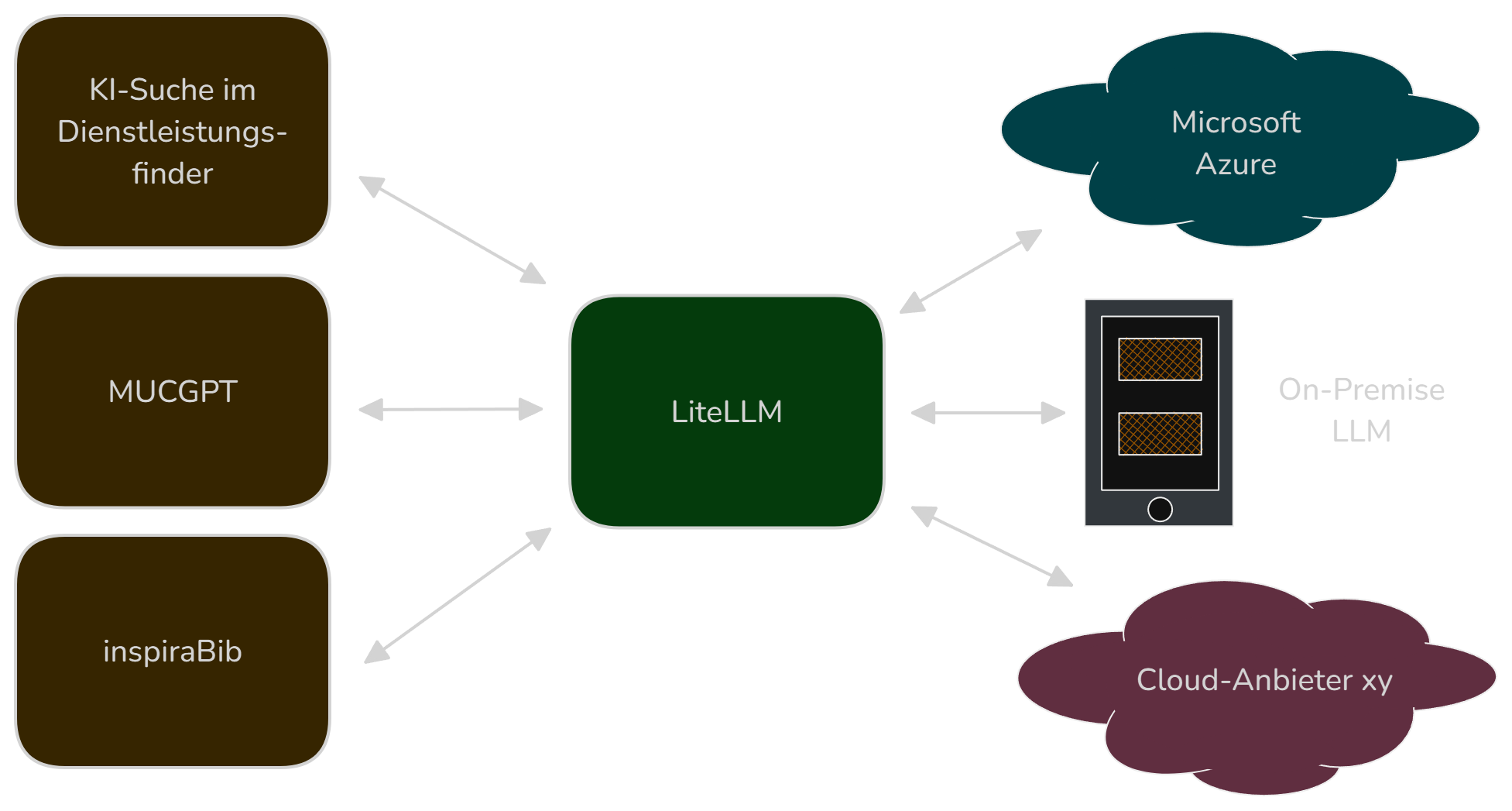
Beispielhafte Verwendung von LiteLLM, Quelle: Eigene Darstellung
Nutzer können einfach virtuelle API-Keys für bestimmte Modelle zugewiesen bekommen. Dies erlaubt das schnelle Ausprobieren von Prototypen. Zusätzlich können Budgets und Ratelimits festgelegt werden.
🔎 Nachvollziehbarkeit & Evaluation: Langfuse
Langfuse ist eine Komponente zur Evaluierung von Sprachmodell Anwendungen. Zwischenschritte in der Logik von KI-Anwendungen können damit nachvollziehbar gespeichert werden. Außerdem können Ergebnisse entweder mit Nutzerfeedback oder mittels KI basierter Evaluatoren bewertet werden. So lässt sich quantitativ nachvollziehen, wie gut eine bestimmte Version des Systems funktioniert.
Für die Entwicklung nutzen wir zusätzlich Datensätze, auf denen einzelne Evaluierungsläufe durchgeführt werden können. Wir nutzen dies beispielsweise, um die Effizienz des Retrievals mit unterschiedlichen Embeddingmodellen zu ermitteln.
Darüber hinaus nutzen wir Langfuse für die Versionierung und das Speichern von Prompts.
📃 Dokumenten-Parsing: Docling
Docling ist ein Open-Source-Tool zur Extraktion und Strukturierung von Informationen aus unterschiedlichen Dokumentenformaten wie PDF, Word oder HTML. In GenAI-Systemen ist es essenziell, Inhalte aus verschiedensten Quellen automatisiert und zuverlässig in ein maschinenlesbares Format zu überführen. Nur so können die Daten effizient vektorisiert, durchsucht und für KI-Anwendungen nutzbar gemacht werden. Docling unterstützt dabei, Metadaten und Textinhalte sauber zu extrahieren und ermöglicht so eine konsistente Weiterverarbeitung in angeschlossenen KI-Systemen.
🌏 Websuche: SearXNG
SearXNG ist eine Open-Source-Metasuchmaschine, die Suchanfragen an verschiedene Anbieter weiterleitet und die Ergebnisse aggregiert. Damit lässt sich Websuche datenschutzfreundlich und unabhängig von großen Suchmaschinen in eigene Systeme integrieren. Im Rahmen unseres GenAI-Stacks planen wir, SearXNG einzusetzen, um aktuelle Webinformationen für KI-Anwendungen bereitzustellen – etwa für RAG-Szenarien. Ein Vorteil: Durch die direkte Abfrage aktueller Daten entfällt das aufwändige Parsen und Speichern großer Datenmengen als Embeddings in einer Vektordatenbank.
Fazit
Der Münchner Open Source GenAI Stack bietet eine flexible und kosteneffiziente Lösung für die Herausforderungen der generativen KI im Enterprise-Bereich. Durch den Einsatz bewährter OSS-Projekte kann die Stadt München ihre digitale Souveränität wahren und gleichzeitig innovative KI-Anwendungen entwickeln.
Die verschiedenen Komponenten des Stacks ermöglichen eine nahtlose Integration und Orchestrierung von KI-Systemen, die für die spezifischen Anforderungen der Stadt angepasst sind. So wird sichergestellt, dass die städtischen KI-Systeme nicht nur leistungsfähig, sondern auch transparent und nachvollziehbar sind.
Autor*innen