KI-Suche im Dienstleistungsfinder
Die KI-Suche im Dienstleistungsfinder nutzt moderne Sprachmodelle, um Bürger*innen bei der Suche nach städtischen Dienstleistungen auf muenchen.de zu unterstützen.
Diese Dokumentation gibt einen Überblick über die Datengrundlage, die technische Funktionsweise sowie die Evaluierung der KI-Suche im Dienstleistungsfinder. Sie dient als Grundlage zum Verständnis des Systems und seiner Leistungsfähigkeit im praktischen Einsatz.
Einführung und Kontext
Die KI-Suche im Dienstleistungsfinder wurde entwickelt, um Bürger*innen sowie Mitarbeitenden der Stadt München einen effizienten und zielgerichteten Zugang zu Informationen über städtische Dienstleistungen zu ermöglichen. Technisch basiert sie auf einem Retrieval-Augmented-Generation-(RAG)-Ansatz, bei dem relevante Dokumente zunächst automatisiert abgerufen und anschließend mithilfe eines großen Sprachmodells kontextualisiert verarbeitet werden. Durch diese Kombination aus Dokumentensuche und generativer KI wird die Qualität der Suchergebnisse deutlich gesteigert und eine präzisere Beantwortung von Suchanfragen ermöglicht.
Datengrundlage
Die KI-Suche basiert auf aktuell auf allen Dienstleistungs-Beschreibungen in Deutsch, die die Stadt München auf ihrer Webseite bereitstellt.
Beispiele für verzeichnete Dienstleistungen
Personalausweis
Deutsche Staatsangehörige sind verpflichtet, einen gültigen Personalausweis (oder Reisepass) zu besitzen, sobald sie 16 Jahre alt sind.
Fischerprüfung
Sie können zur Fischerprüfung zugelassen werden, wenn Sie vorher an einem anerkannten Vorbereitungslehrgang nach Ausbildungsplan teilgenommen haben.
Temporäre Kanalanschlüsse
Wenn Sie Baustelleneinrichtungen oder Veranstaltungen (Straßenfeste, etc.) planen, können Sie temporäre Kanalanschlüsse für Sanitärcontainer anfordern.
Funktionsweise
Die zu Beginn eingeführte Retrieval-Augmented-Generation-(RAG)-Methodik bildet die Grundlage der KI-Suche. Dabei werden in einem ersten Schritt zu einer Nutzeranfrage relevante Dokumente aus der zugrunde liegenden Datenbasis abgerufen. Anschließend werden auf Basis der relevantesten Dokumente mithilfe eines großen Sprachmodells (LLM) kontextbezogene Antworten generiert.
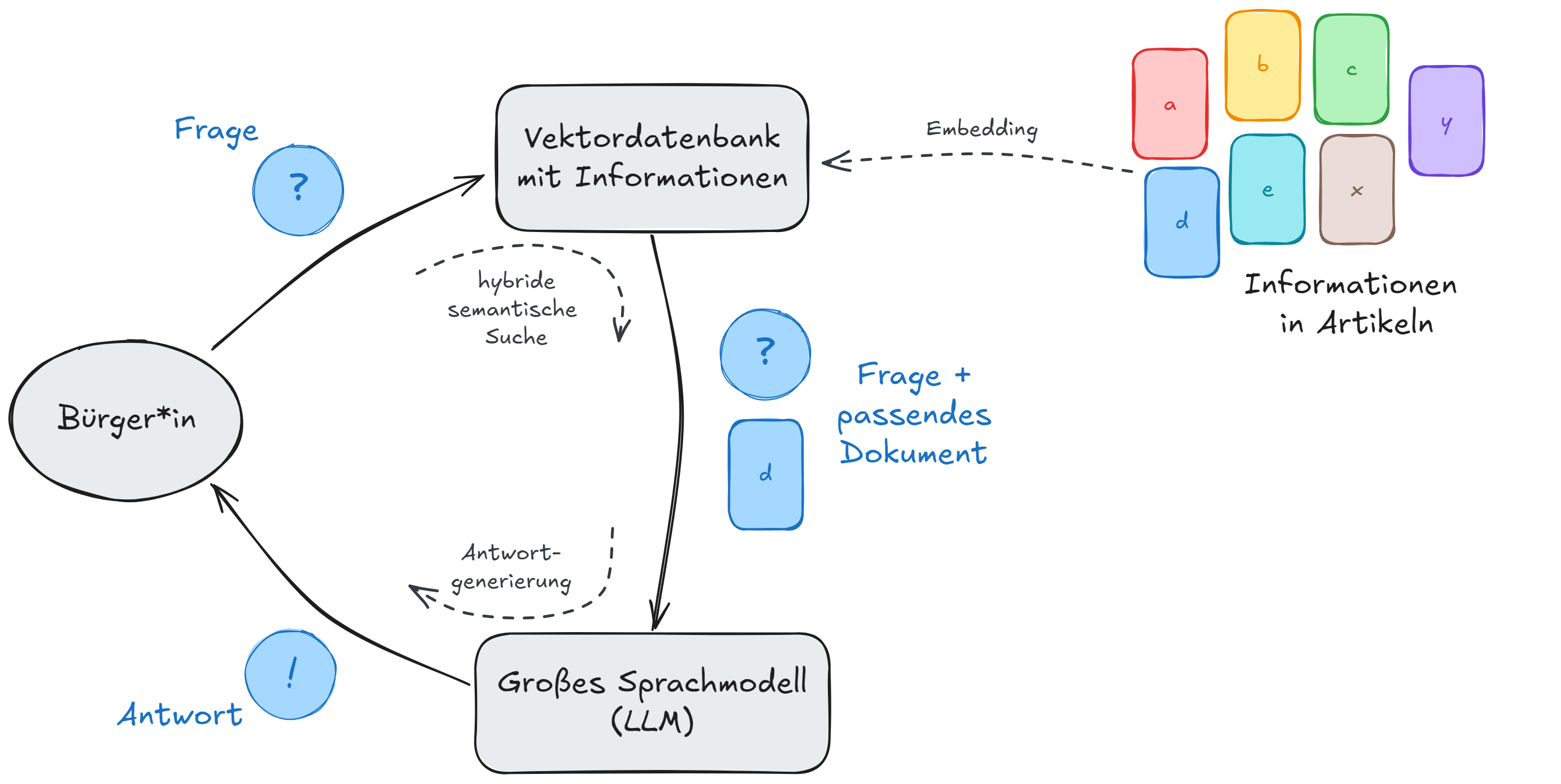
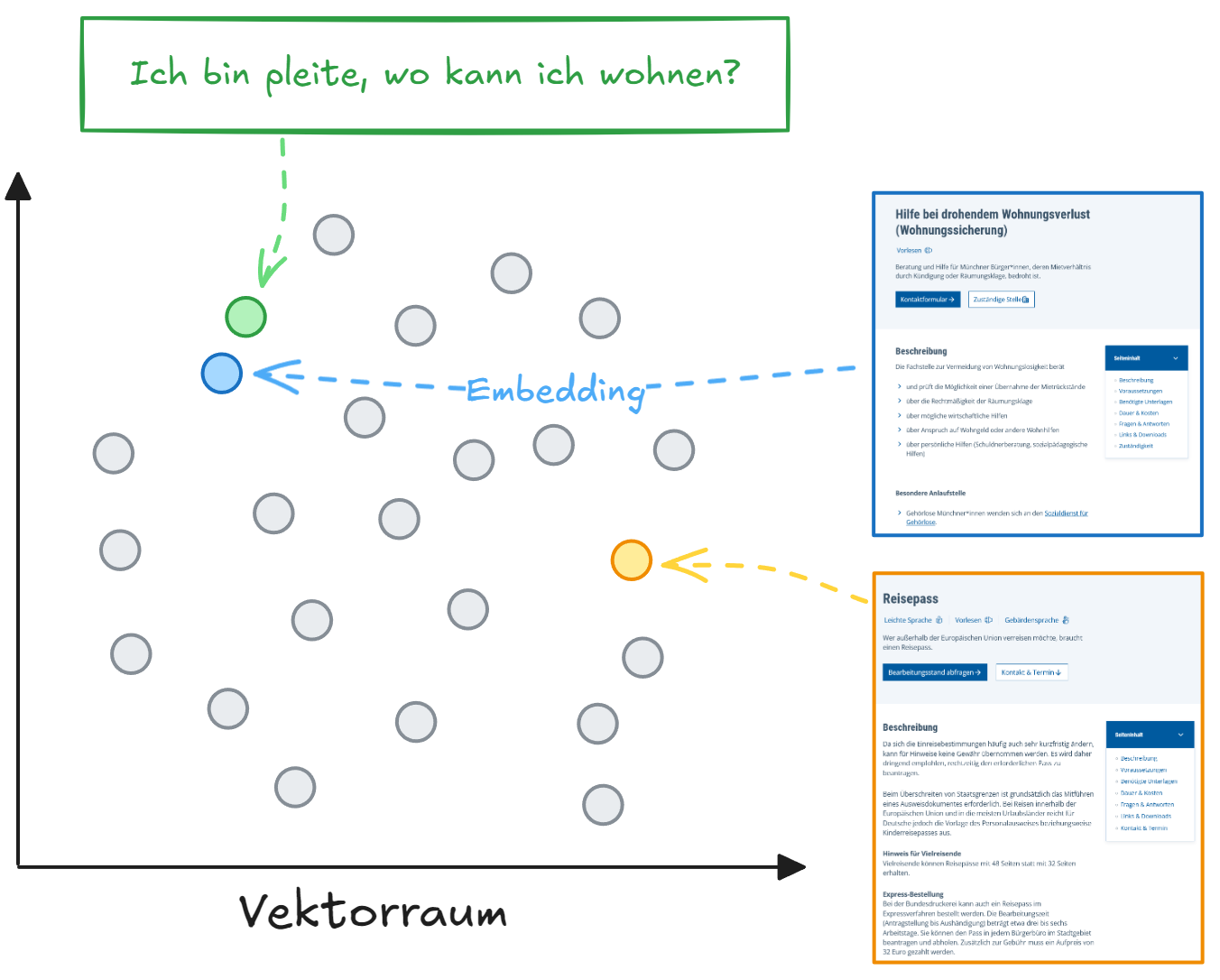
Repräsentation der semantischen Information mit Embeddings
Die KI-Suche nutzt zum Vergleich der Informationen in den Dokumenten und der Nutzeranfrage Embeddings. Embeddings sind hochdimensionale Vektoren, die durch ein spezielles KI-Modell generiert werden. Als Eingabe erhält das Embedding-Modell einen Text (z.B. die Dienstleistungsbeschreibung) und gibt einen Vektor zurück. Diese Vektoren können dann in einer Datenbank gespeichert und einfach verglichen werden, um die Ähnlichkeit zwischen verschiedenen Texten zu bestimmen.
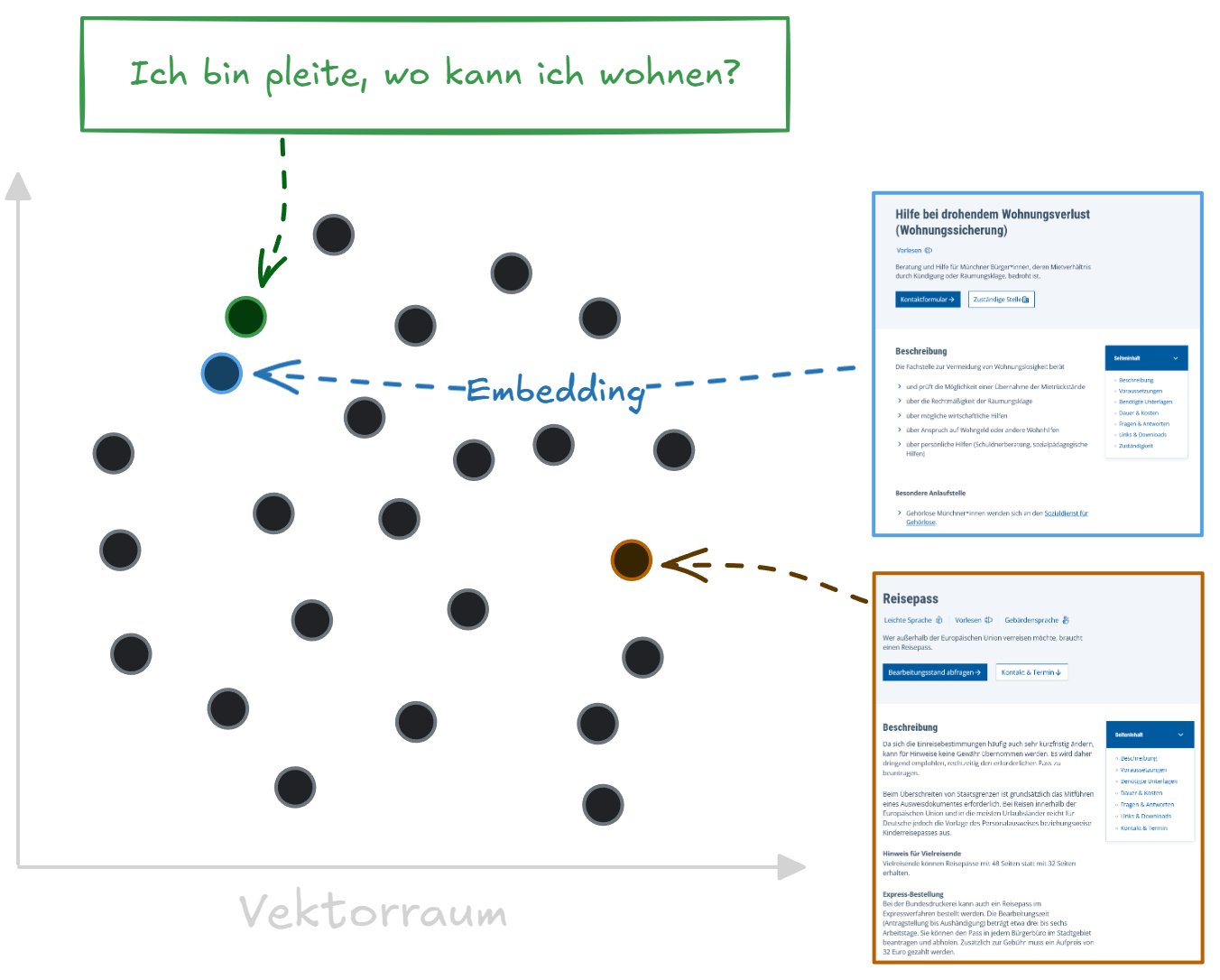
Hybride Suche mit BM25
In dieser Anwendung wird eine hybride Suchmethode verwendet. Sie kombiniert die klassische, stichwortbasierte Methodik BM25 mit den oben beschriebenen semantischen Embeddings. So können sowohl zu klassischen Suchanfragen, als auch ausformulierte Fragen, die keine exakten Schlüsselwörter enthalten, Dokumente gefunden werden.
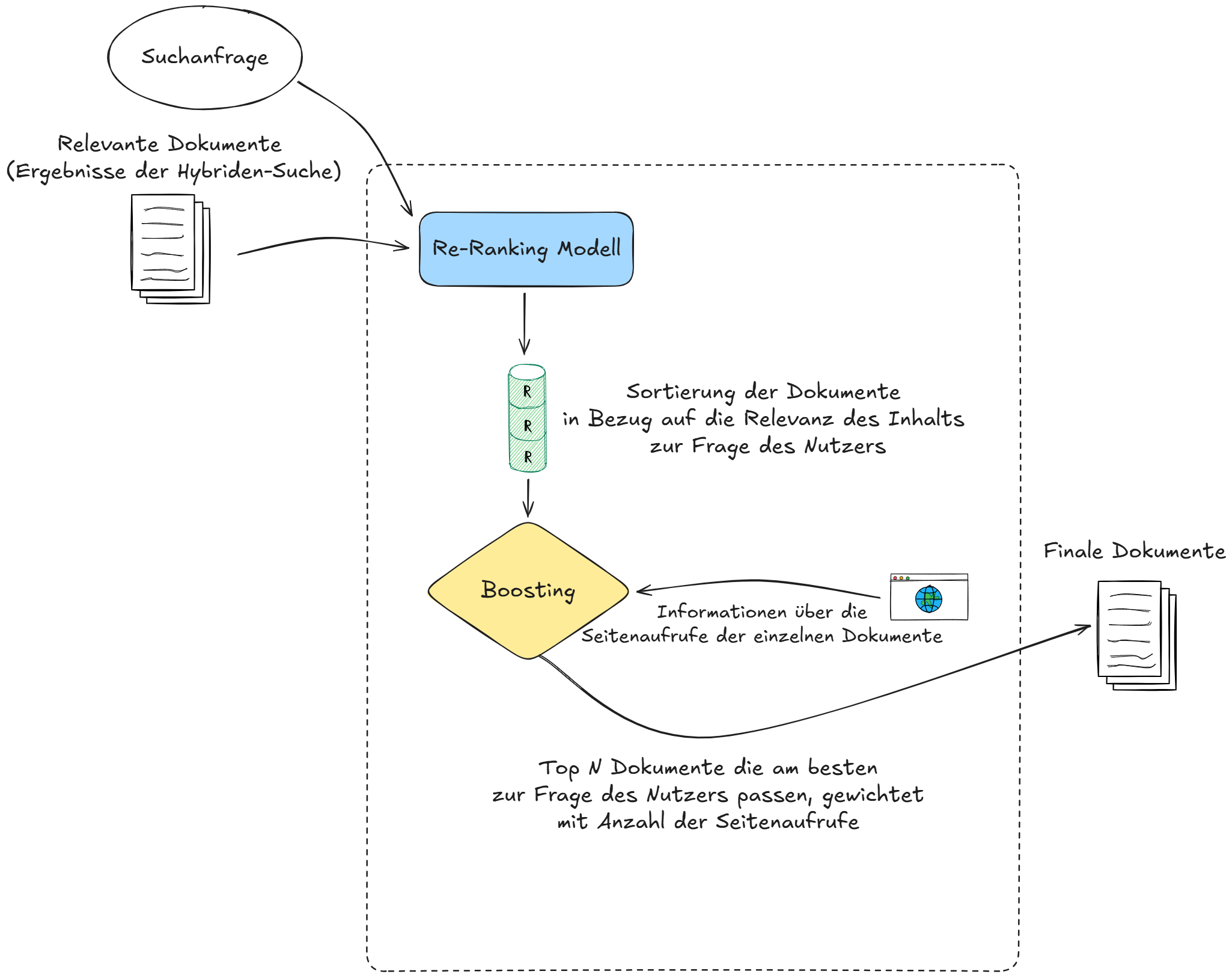
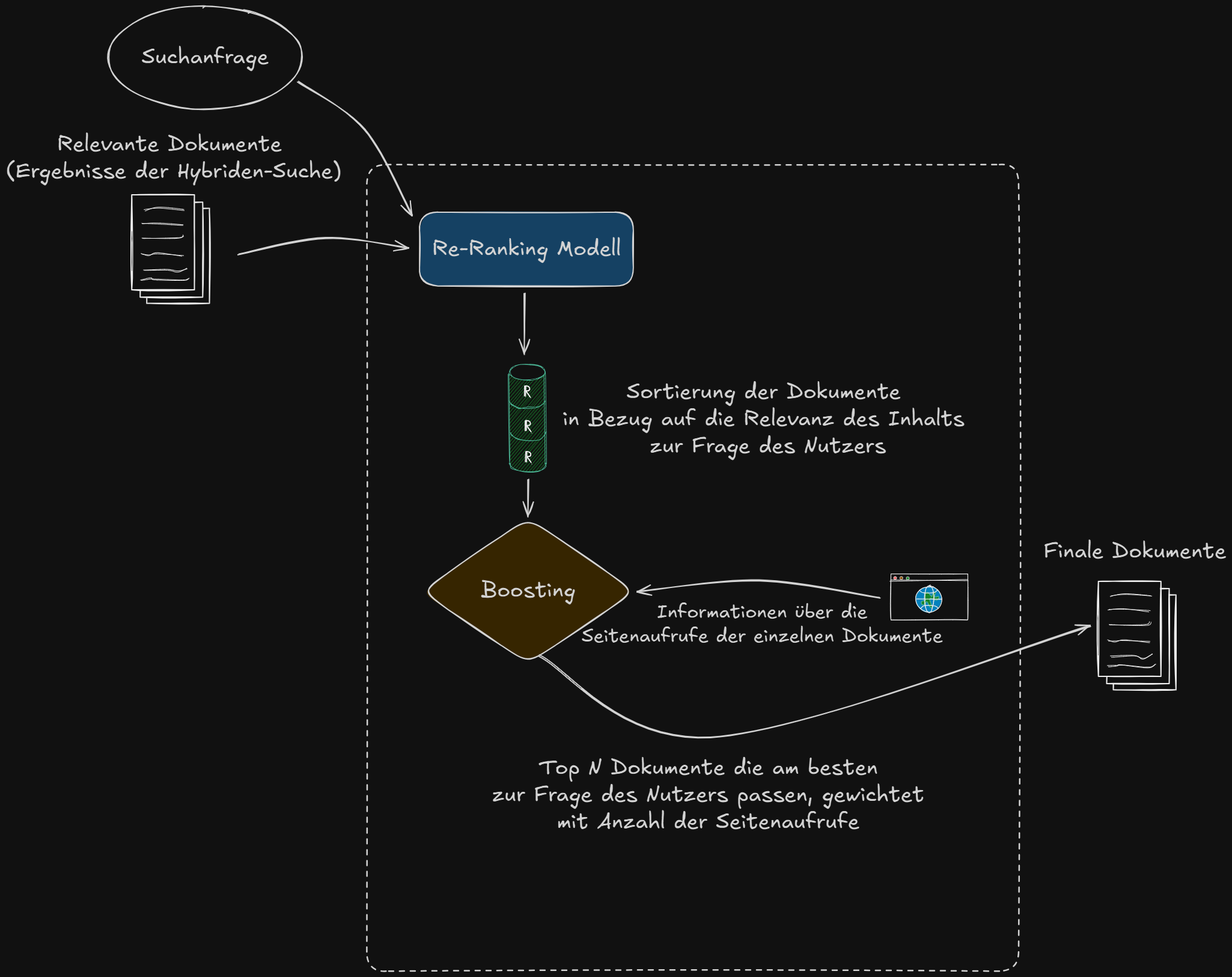
Relevanzbasierte Sortierung der Dokumente mittels Re-Ranking und Boosting
Zur Optimierung der Ergebnisreihenfolge werden die gefundenen Dokumente mithilfe eines Re-Ranking-Modells anhand ihrer inhaltlichen Relevanz zur Nutzeranfrage neu sortiert. Dadurch wird sichergestellt, dass inhaltlich präzisere und für die Anfrage relevantere Dokumente bevorzugt platziert werden.
Ergänzend zum Re-Ranking werden die Suchergebnisse auf Basis aktueller Seitenaufrufe gewichtet. Dokumente mit einer hohen Anzahl an Seitenaufrufen werden dabei priorisiert und entsprechend höher in den Suchergebnissen platziert als weniger häufig aufgerufene Inhalte.
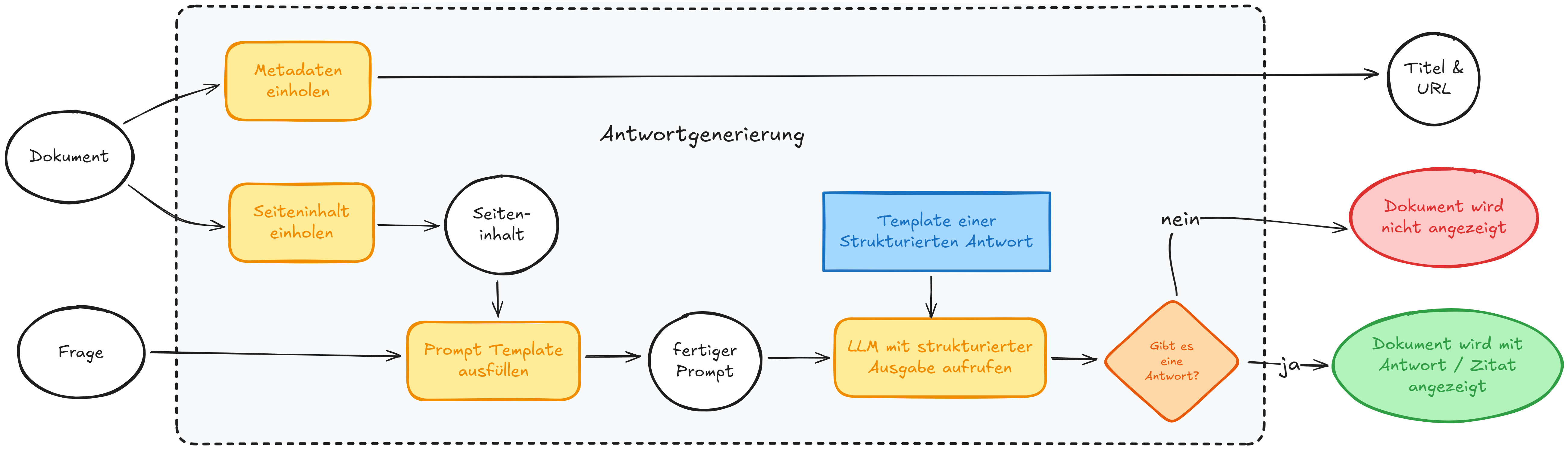
Generierung der Antwort
Für jedes aus der Suche extrahierte Dokument wird ein großes Sprachmodell (engl. Large Language Model, LLM) aufgerufen. Basierend auf der Nutzeranfrage und dem jeweiligen Dokumenteninhalt erzeugt das LLM drei Ausgaben:
- eine ausformulierte Antwort auf die gestellte Frage,
- ein inhaltlich passendes wörtliches Zitat aus dem Dokument,
- eine Einschätzung, ob das Dokument zur Beantwortung der Frage geeignet ist.
Kann die Frage anhand eines Dokuments nicht beantwortet werden, wird dieses nicht angezeigt. Auf diese Weise wird sichergestellt, dass Suchergebnisse, die trotz Re-Ranking und Boosting nicht ausreichend relevant für eine präzise Beantwortung der Anfrage sind, nicht an die Nutzer*innen zurückgegeben werden.
KI-Modelle
Embedding-Modell
Semantische Vektoren von Texten (Text-Embeddings) erfassen die inhaltliche Ähnlichkeit zwischen Texten. In dieser Anwendung werden sie genutzt, um zu einer Suchanfrage relevante Dokumente zu identifizieren. Hierfür verwendet das System das Embedding-Modell „text-embedding-3-large“ von OpenAI. Mehr Informationen zum Modell
Großes Sprachmodell (LLM)
Das große Sprachmodell "gpt-4.1-mini" von OpenAI wird zur Generierung der Nutzerantworten genutzt. Mehr Informationen zum Modell
Evaluation
Datensätze für die Evaluation
Für die Evaluation werden zwei Datensätze herangezogen. Einer dieser Datensätze wurde mithilfe eines Large Language Models (LLM) generiert, während ein weiterer Datensatz als manuell erstellter Goldstandard für die Dienstleistungsartikel dient.
Im Überblick kommen folgende Datensätze zum Einsatz:
- LHMDienstleistungenQA: Händisch erstellter Goldstandard-Datensatz
- Query-Doc-Service-de: Automatisch generierter Datensatz
Aufgrund kontinuierlicher inhaltlicher und struktureller Aktualisierungen der Dienstleistungsartikel enthalten beide Datensätze Beispiele mit nicht mehr aktuellen Dokumenttiteln. In diesen Fällen ergibt die Evaluation formal einen Wert von 0, selbst wenn das inhaltlich korrekte Dokument erfolgreich abgerufen wurde. Um diesen Effekt zu mitigieren, wird bei fehlender direkter Dokumentübereinstimmung zusätzlich die Ähnlichkeit zwischen dem erwarteten und dem abgerufenen Dokumenttitel berücksichtigt.
Ergebnisse der Evaluation
Zur Bewertung der Retrieval-Leistung werden der Mean Reciprocal Rank (MRR) sowie der Recall@10 herangezogen. Die Ergebnisse sind in folgender Tabelle zusammengefasst:
| LHMDienstleistungenQA | Query-Doc-Service-de | |
|---|---|---|
| MRR | 0.6735 | 0.6618 |
| Recall@10 | 86.20 % | 83.33 % |
Der Mean Reciprocal Rank liegt im Bereich zwischen 0 und 1 und misst, wie hoch das relevante Dokument in der Ergebnisliste des Retrievals platziert ist. Ein MRR von 1.0 bedeutet, dass das relevante Dokument an erster Stelle platziert ist, während ein Wert von 0.5 einer Platzierung an zweiter Stelle entspricht. Der Recall@10 gibt an, in wie vielen Fällen sich das relevante Dokument unter den ersten zehn Suchergebnissen befindet.
Die dargestellten Ergebnisse beziehen sich ausschließlich auf die Leistung der Retrieval-Komponente. Im Produktivsystem wird nach dem Retrieval eine zusätzliche Relevanzklassifikationsstufe eingesetzt, die irrelevante Dokumente herausfiltert und das relevanteste Dokument gegebenenfalls an die oberste Position verschiebt. Entsprechend kann sich das den Nutzern präsentierte Ranking vom durch den MRR gemessenen Roh-Retrieval-Ranking unterscheiden.
Der Datensatz Query-Doc-Service-de wurde mithilfe eines LLM generiert. Da diese Modelle nicht über explizites Expertenwissen zu den zugrunde liegenden Artikeln verfügen, können einzelne generierte Fragen nur teilweise mit den Dokumentinhalten übereinstimmen, was das Retrieval negativ beeinflussen kann. Gleichzeitig können solche Fragen jedoch die Mehrdeutigkeit und Variabilität realer Nutzeranfragen besser widerspiegeln als Experten-Fragen zu den jeweiligen Dokumenten.
Die Evaluation wurde mit der vollständigen produktiven Retrieval-Pipeline durchgeführt, einschließlich Re-Ranking und popularitätsbasiertem Dokument-Boosting. Diese Boosting-Strategie priorisiert häufig aufgerufene Artikel, was auf eine höhere Nützlichkeit für Nutzer hindeuten kann. Uns ist bewusst, dass eine auf aktuellen Zugriffszahlen basierende Gewichtung langfristig einen Bias verursachen kann, da häufig priorisierte Artikel tendenziell mehr Aufrufe generieren. Alternative Boosting-Strategien werden derzeit untersucht.
Unter diesen Rahmenbedingungen weist ein durchschnittlicher MRR von 0.67 auf eine stabile und qualitativ hochwertige Platzierung relevanter Dokumente im Retrieval hin und wird durch einen Recall@10 von konsistent über 80 % bestätigt. Diese Kombination zeigt, dass relevante Dokumente in der Regel hoch gerankt sind und nahezu immer im initialen Kandidatenset enthalten sind, wodurch eine effektive nachgelagerte Relevanzfilterung ermöglicht wird.
Beispieleinträge aus dem Goldstandard-Datensatz
| Frage | Zugehöriges Dokument |
|---|---|
| Was passiert mit dem Biomüll? | Biotonne anmelden oder ummelden |
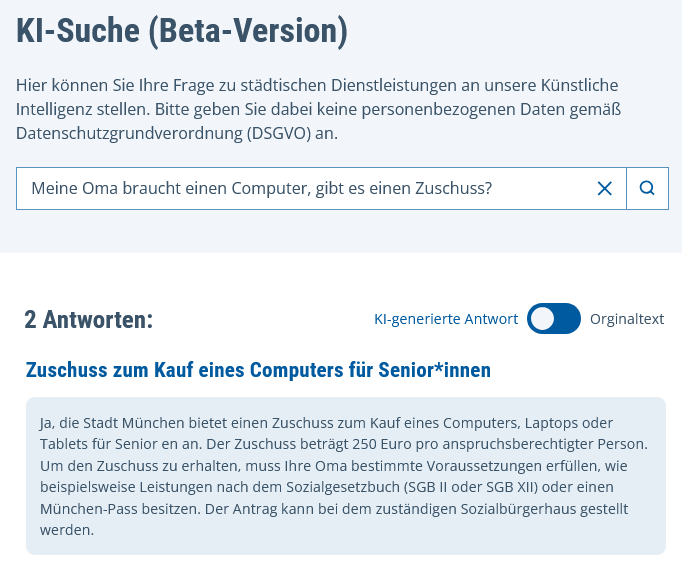
| Meine Oma braucht einen Computer, gibt es einen Zuschuss? | Zuschuss zum Kauf eines Computers für Senior*innen |
| Was macht der Arzt bei der Untersuchung bevor mein Kind in die Schule kommt? | Reformierte Gesundheitsuntersuchung zur Einschulung |
| Wie tausche ich meinen alten Lappen um? | Umtausch in Kartenführerschein |
Risiken und Limitierungen
Obwohl die KI-Suche viele Vorteile bietet, gibt es auch einige Risiken und Limitierungen:
- Bias in den Daten: Die KI-Modelle können Vorurteile aus ihren Trainingsdaten übernehmen.
- Sprachliche Beschränkungen: Die Qualität der Antworten kann je nach Sprache und Formulierung der Anfrage variieren.
- Datenschutz: Es dürfen keine personenbezogenen Daten eingegeben werden.