Verkehrsdaten-Plausibilisierung
Dieses System nutzt Machine Learning zur automatisierten Plausibilisierung von Verkehrsdaten, um die Qualität städtischer Mobilitätsinformationen sicherzustellen.
Verkehrsdaten sind für Planung, Wissenschaft, Verwaltung, Politik und Bevölkerung von großem Interesse und unerlässlich für regionale und städtische Verkehrsprojekte sowie zur Bewertung von bspw. Klimaschutzmaßnahmen.
Um qualitativ hochwertige Verkehrsinformationen zu gewährleisten, müssen die Daten regelmäßig auf Störungen (z.B. Beschädigung, Fehler bei der Datenübertragung) und besondere Verkehrssituationen (z.B. Unfall, Stau) geprüft werden. Aufgrund der großen Datenmengen ist ein automatisiertes Verfahren zur Plausibilisierung notwendig.
Datengrundlage
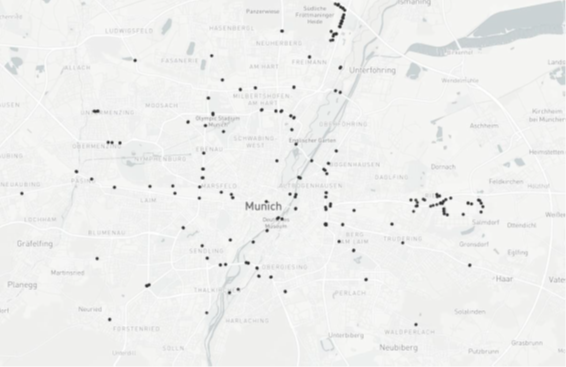
Standorte der Messstellen in München
In München sind etwa 100 Messstellen zur Erfassung des Kfz-Verkehrs mittels Induktionsschleifen installiert. Diese erfassen die Anzahl und Art der Fahrzeuge in 15-Minuten-Intervallen. Die Daten müssen regelmäßig auf Störungen und besondere Verkehrssituationen geprüft werden, um qualitativ hochwertige Verkehrsinformationen zu gewährleisten.
Bilder der Sensorik


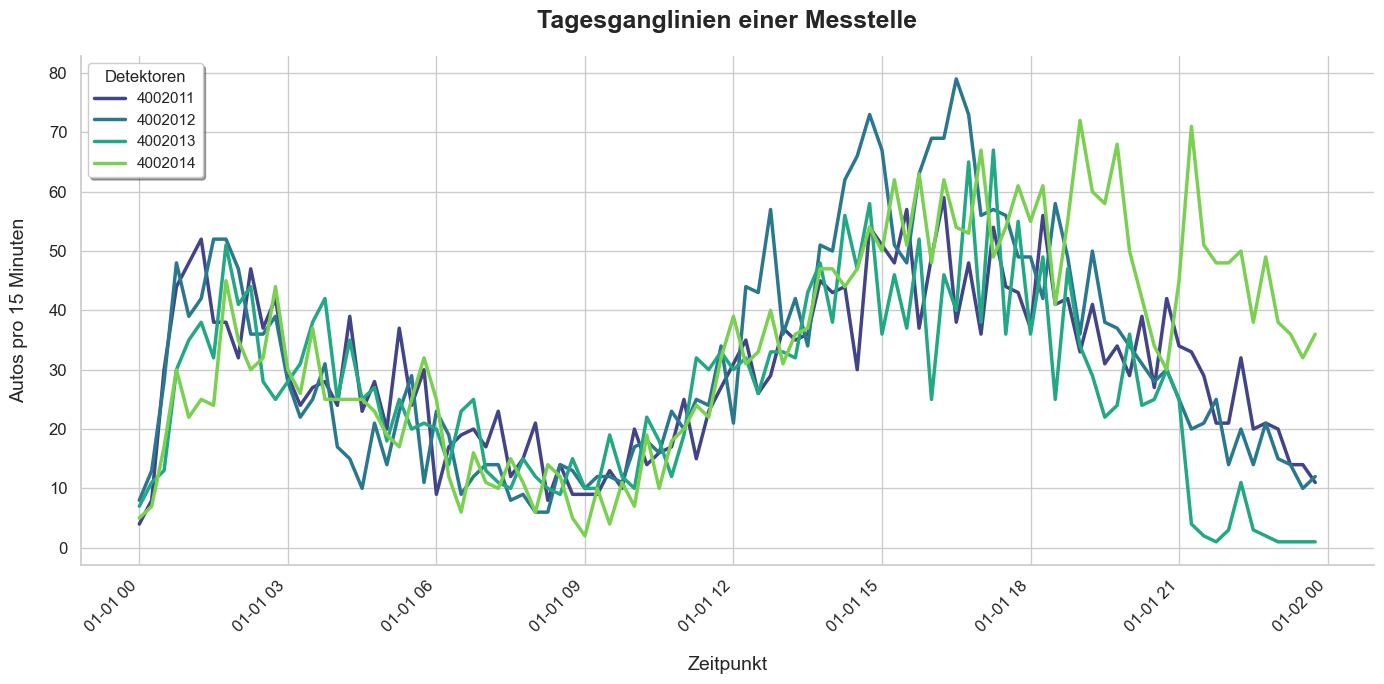
Ganglinien der Detektoren einer Messtelle
Beispielhafte Ganglinie einer Messtelle mit 4 Fahrstreifen/Detektoren.
Funktionsweise
Überprüfung der Sensordaten
Die Daten jedes Detektors werden einmal täglich auf Auffälligkeiten überprüft. Dazu werden zwei Prüfmechanismen verwendet:
- Nullwertregel: Durch die Festlegung von Schwellenwerten für die pro Tag zulässigen Nullwerte, basierend auf dem durchschnittlichen Verkehrsaufkommen des Sensors, werden Komplettausfälle erkannt. Sensoren, die diese Schwellenwerte überschreiten, werden als auffällig gekennzeichnet.
- Intervallregel: Für jeden Detektor wird täglich ein Machine-Learning-Modell trainiert, das ein Intervall für den typischen Verkehrsverlauf des Tages prognostiziert. Messwerte, die außerhalb dieses Intervalls liegen, werden gezählt, und Sensoren, die einen festgelegten Grenzwert überschreiten, werden als auffällig gekennzeichnet.
Beispiel
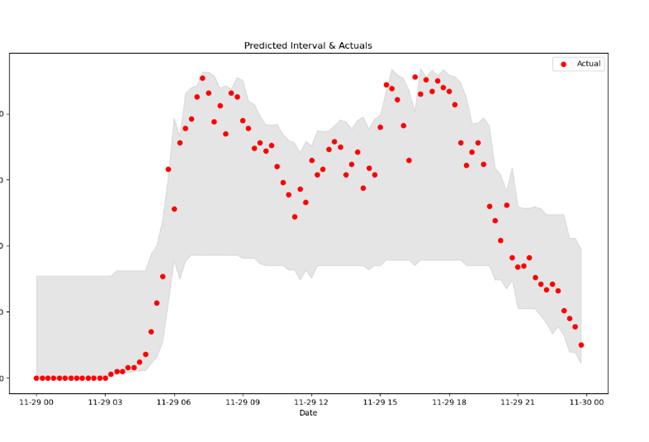
Ergebnisse der Datenprüfung
Auffällige Daten werden speziell markiert, wenn sie signifikant vom durchschnittlichen Verkehrsaufkommen abweichen. Diese markierten Daten können anschließend ausgeschlossen werden, um die Datenqualität und Genauigkeit der Datenanalyse zu verbessern.
Visualisierung durch Dashboards
Die Überprüfungsfunktion des Modells erstellt Dashboards, um den Fachbereichen detaillierte Einblicke in die Häufigkeit von Auffälligkeiten zu geben. So können auffällige Sensoren schnell erkannt und Ursachen für Abweichungen gründlich untersucht werden.
Evaluation
Die Plausibilisierungs-Komponente wurde mithilfe des Fachbereichs getestet und evaluiert. Die Genauigkeit des Algorithmus ist schwer exakt zu bestimmen, da neben den Sensorzählungen keine vergleichbaren alternativen Zählungen existieren.
Beispiel Datensatz
| datetime | 4001011 | 4001012 | 4001013 | 4001014 |
|---|---|---|---|---|
| 2016-01-01 00:00:00 | 8 | 9 | 10 | 3 |
| 2016-01-01 00:15:00 | 7 | 20 | 5 | 3 |
| 2016-01-01 00:30:00 | 14 | 19 | 11 | 10 |
| 2016-01-01 00:45:00 | 21 | 33 | 12 | 20 |
| 2016-01-01 01:00:00 | 21 | 21 | 21 | 12 |
| 2016-01-01 01:15:00 | 28 | 42 | 33 | 34 |
| 2016-01-01 01:30:00 | 27 | 34 | 24 | 20 |
| 2016-01-01 01:45:00 | 33 | 30 | 24 | 32 |
Risiken und Limitierungen
Obwohl der Plausibilisierungsservice viele Vorteile bietet, können Fehler des Systems nicht gänzlich ausgeschlossen werden. Da es nur sehr begrenzte manuelle Vergleichszählungen gibt, konnte der Algorithmus nicht mit einem typischen Testdatensatz evaluiert werden.